
Introduction to Robots.txt
Robots.txt is a simple text file placed in a website’s root directory that instructs search engine bots which pages or sections to crawl or avoid. It helps control crawler access, preventing indexing of sensitive or duplicate content. Over 90% of websites use robots.txt to manage bot traffic and optimize crawl budgets. When a crawler visits a site, it first checks robots.txt to follow its directives, improving site security and SEO efficiency. Proper configuration avoids accidental blocking of important pages and ensures better indexing, ultimately enhancing search engine rankings and user experience.
In the world of SEO and website management, understanding “what is robots.txt” is essential. Whether you run a global SaaS platform, a rapidly scaling eCommerce brand, or manage enterprise-level corporate sites, the robots.txt file plays a vital role in search engine visibility, crawl efficiency, and content security.
The robots.txt file is a fundamental part of technical SEO. Despite its simplicity, it can significantly influence how search engines interact with your website. According to SEMrush, approximately 95% of websites use robots.txt files to guide search engines on which parts of their site to crawling and indexing.
As Google continues to evolve its AI algorithms and prioritize structured, optimized content delivery, the role of robots.txt in SEO has become more strategic than ever before.
What is Robots.txt and Its Purpose?
Robots.txt is a plain text file located in the root directory of your website (e.g., www.yourdomain.com/robots.txt). Its primary function is to communicate with search engine bots (also known as crawlers or user-agents) about which pages or sections of a site should or should not be crawled.
Purpose of Robots.txt:
- Control crawler access to specific parts of your website
- Preserve crawl budget by restricting unimportant or redundant content
- Protect sensitive data or duplicate pages from being indexed
- Direct bots to important resources like your XML sitemap
This small file serves as the first handshake between your site and the crawler before any indexing takes place.
Google Search Central defines robots.txt as a file that “gives instructions about their site to web robots.”
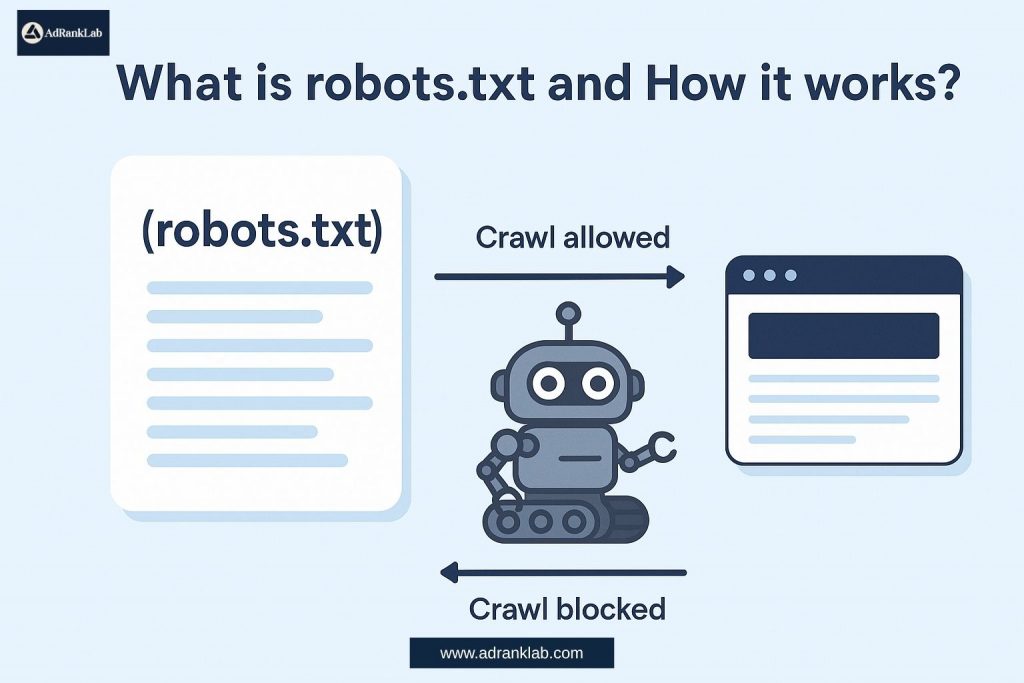
How Robots.txt Works
To understand how robots.txt works, it’s important to know how web crawlers operate. Crawlers like Googlebot, Bingbot, or YandexBot scan your website content for indexing and ranking. Before accessing your pages, they check the robots.txt file for permission.
Key Concepts:
User-agent:
Specifies the name of the crawler (e.g., Googlebot, Bingbot, * for all bots)
Disallow:
Tells the crawler not to access a particular URL or directory
Allow:
Overrides Disallow in specific conditions (only applicable to Googlebot and some others)
Sitemap:
Provides the crawler with the location of your XML sitemap
Example of Robots.txt Syntax:
User-agent: *
Disallow: /private/
Allow: /private/public-info.html
Sitemap: https://www.example.com/sitemap.xmlReal-World Sources:
Google’s Robots.txt specifications clearly explain that crawlers adhere to these rules to avoid overloading servers and to respect website owners’ preferences.
Benefits of Robots.txt for SEO
Using robots.txt strategically can enhance your website’s SEO in several ways:
1. Optimize Crawl Budget
Search engines allocate a crawl budget based on your site’s size, authority, and update frequency. Robots.txt ensures crawlers focus only on valuable content.
2. Prevent Duplicate Content Indexing
By disallowing pages like filters, tags, or print versions, you avoid duplicate content, which can confuse Google and dilute rankings.
3. Improve Site Security and Privacy
Block sensitive areas like /admin/, /wp-login.php, or internal documentation that shouldn’t be public-facing.
Fact: According to Google Search Central, Googlebot obeys robots.txt rules over 90% of the time, reinforcing its trustworthiness.
Best Practices for Robots.txt
To gain the full SEO value of robots.txt, follow these best practices:
When to Use Disallow
- Duplicate pages (e.g., print versions)
- Internal search results
- Admin directories
- Low-value scripts or assets
When to Use Allow
- Exception pages inside disallowed folders
- Useful resources (e.g., documentation or PDFs)
Structure Tips
- Keep it simple and consistent
- Group rules by user-agent
- Always end with a sitemap URL
✅ Tools for Robots.txt Validation
- Google Search Console Robots.txt Tester
- Yoast SEO Plugin
- Screaming Frog SEO Spider
Common Robots.txt Mistakes and Their Impact
A misconfigured robots.txt file can lead to serious SEO issues.
Blocking Important Pages
Accidentally disallowing your /blog/ or /product/ pages can deindex crucial revenue-generating content.
Syntax Errors
Using incorrect syntax like Disallow:/blog (missing space) or incorrect wildcard usage can break the file.
Real Case Study: BMW.de
In 2006, BMW.de blocked Googlebot entirely due to improper directives in their robots.txt file. This mistake resulted in a temporary deindexing of the entire site from Google.
Tip: Always test updates before deploying them.
How to Create and Test a Robots.txt File
Step-by-Step Creation Guide:
- Open a plain text editor (e.g., Notepad or VS Code)
- Use correct syntax and logic based on your site’s needs
- Save as
robots.txt - Upload to the root directory:
https://yourdomain.com/robots.txt
Tools for Testing:
- Google Search Console Robots.txt Tester
- Screaming Frog Custom Extraction
- Yoast SEO File Editor
Tip: Check server headers to confirm the robots.txt file is returning a 200 OK status.
Advanced Robots.txt Use Cases
1. Controlling AI Bots and Scrapers
Block known scraping bots using user-agent rules:
User-agent: MJ12bot
Disallow: /2. Managing Staging Environments
Prevent staging or dev environments from being indexed:
User-agent: *
Disallow: /3. Custom Directives for Specific Bots
Fine-tune access for Googlebot vs Bingbot with separate rulesets.
Fact: Googlebot and Bingbot support advanced directives like Allow and wildcards, but other bots might not.
Robots.txt vs Noindex: What’s the Difference?
Robots.txt:
- Prevents crawling of a page
- Does not prevent indexing if the page is linked elsewhere
Noindex Tag:
- Allows crawling but prevents indexing
Use-Case Example:
- Use
robots.txtto block pages with infinite filters - Use
noindexto prevent indexing of legal disclaimers or T&C pages
SEO Tip: Never block a page in robots.txt if you’re using noindex on that same page. Google can’t see the noindex if it can’t crawl the page.
AI and Robots.txt in 2025
As AI-based crawlers like OpenAI’s GPTBot or Anthropic’s ClaudeBot become more prevalent, websites need smarter robots.txt strategies.
Emerging Trends:
- More bots respect custom rules
- New
user-agentidentifiers for AI crawlers - Shift toward API access control and structured data tagging
Future-Proofing Tips:
- Monitor server logs for unknown bots
- Update
robots.txtregularly with new AI bots - Stay informed with Google’s Robots.txt changelogs
Stat: Statista projects AI bots will account for 40% of total non-human traffic by 2026.
FAQ Section
Q1: What happens if you don’t use robots.txt? Search engines will crawl your entire site. This could lead to wasted crawl budget and unwanted indexing of sensitive content.
Q2: Can robots.txt block all bots? No. While ethical bots like Googlebot obey robots.txt, malicious bots or scrapers often ignore it.
Q3: How to check if Google is respecting robots.txt? Use Google Search Console’s URL Inspection Tool and Robots.txt Tester.
Q4: Can I use robots.txt to improve my rankings? Indirectly. Robots.txt optimizes crawl budget and keeps search engines focused on high-value content, which can lead to better rankings.
Q5: Is robots.txt required for every site? No, but it’s highly recommended, especially for large websites or sites with sensitive directories.
Conclusion: Master Robots.txt for SEO Success
Understanding what is robots.txt and how it works is crucial for any organization aiming for digital success in 2025. This humble text file helps control crawler access, improve SEO hygiene, protect private data, and optimize crawl budgets — all of which contribute to higher visibility and improved rankings.
At AdRankLab, we specialize in technical SEO audits, crawl diagnostics, and robots.txt optimization tailored for global businesses. Don’t let a small mistake block your big results.
🚀 Get your robots.txt optimized by experts. Contact AdRankLab today for a free technical SEO consultation.
Keyword Tags: what is robots.txt, how robots.txt works, disallow in robots.txt, robots.txt SEO, block pages from Google, control web crawler access, crawl directives, robots.txt examples

2 thoughts on “What is Robots.txt and How It Works?”